近期,一款由中国新兴AI企业DeepSeek研发的开源大模型DeepSeek-V3,在全球范围内引起了广泛关注。这款模型不仅性能卓越,而且训练成本相对较低,给业界带来了不小的震动。
据悉,DeepSeek-V3的技术论文详细披露了该模型的研发历程。与上一代相比,其参数规模从2360亿大幅提升至6710亿,并在14.8T tokens的数据集上进行了预训练,上下文长度更是达到了128K。这一系列的升级,使得DeepSeek-V3在多个主流评测基准上表现出色,性能媲美甚至超越了GPT-4o和Claude-3.5-Sonnet等领先的闭源模型。
DeepSeek-V3的出色表现,也吸引了众多AI领域的大咖关注。其中包括阿里前副总裁贾扬清、metaAI科学家田渊栋、英伟达高级研究科学家Jim Fan等。这些专家对DeepSeek-V3给予了高度评价,甚至有网友将其誉为“全球最佳开源大模型”,并预测它将加速AGI(通用人工智能)的实现。
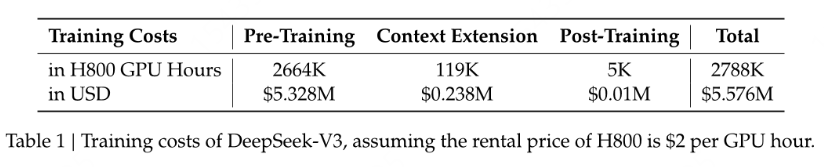
值得注意的是,DeepSeek-V3的训练成本相对较低,是其受到广泛关注的重要原因之一。据透露,该模型仅使用了2000多张GPU,训练成本不到600万美元,远低于OpenAI、meta等在万卡规模上训练的模型成本。这种成本效益比,让DeepSeek-V3在业界独树一帜。
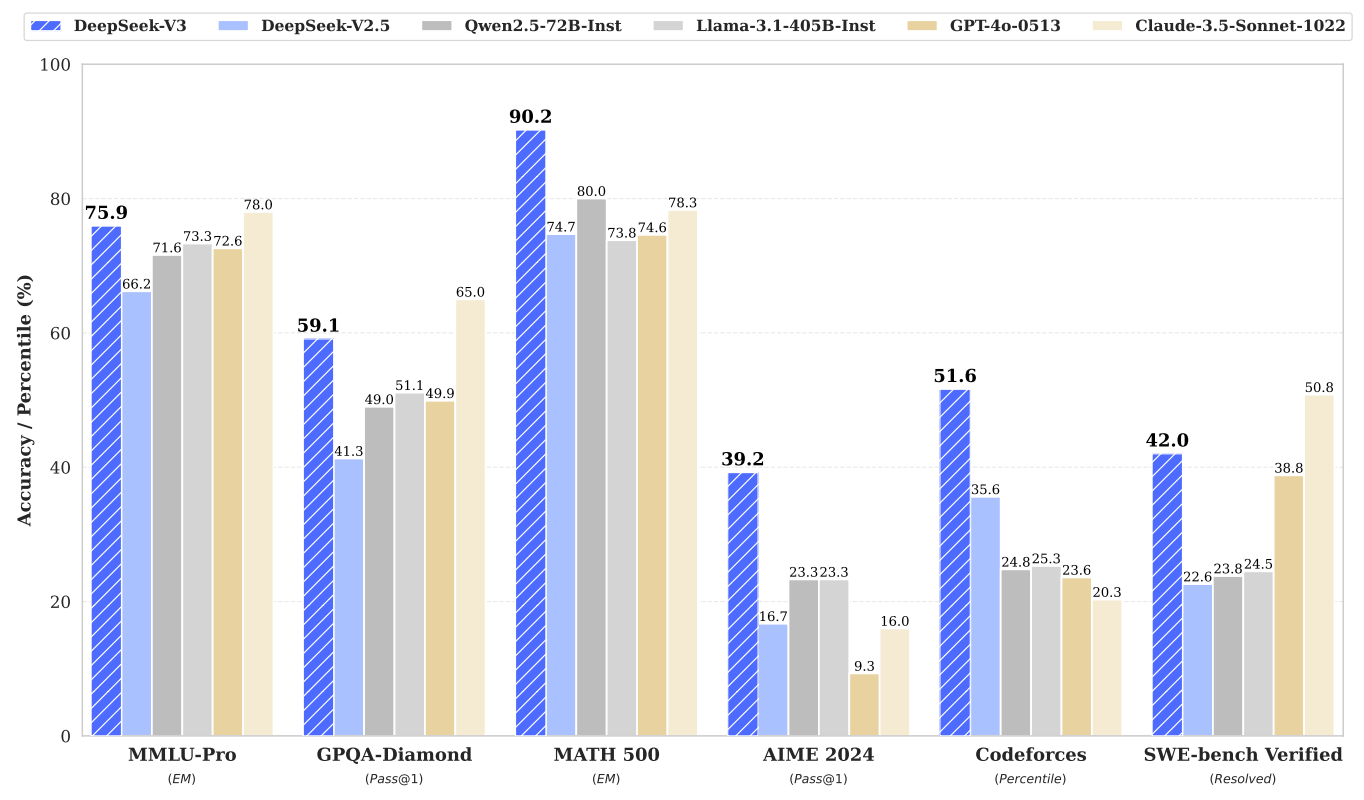
在知识能力方面,DeepSeek-V3同样表现出色。在MMLU-Pro和GPQA-Diamond等基准测试中,它超越了阿里、meta等所有开源模型,并接近GPT-4o的水平,尽管略逊于Claude-3.5-Sonnet。而在数学、代码和推理能力方面,DeepSeek-V3更是展现出了强大的实力。在MATH500、AIME2024及Codeforces等多个主流基准测试中,它不仅碾压了阿里和meta的最新开源模型,还超越了GPT-4o和Claude-3.5-Sonnet,成为业界的新标杆。
然而,DeepSeek-V3也并非完美无缺。它在某些方面还存在局限性。例如,在英文能力方面,它还落后于GPT-4o和Claude-Sonnet-3.5。同时,该模型的部署要求较高,对小型团队不太友好。其生成速度也有待进一步提升。不过,DeepSeek在论文中表示,随着更先进硬件的开发,这些局限性有望在未来得到解决。
尽管存在这些局限性,但DeepSeek-V3的出现无疑为AI领域带来了新的活力和希望。它展示了中国在AI技术研发方面的实力和潜力,也为其他国家和地区提供了宝贵的借鉴和启示。未来,我们期待DeepSeek-V3能够不断完善和提升自己,为AI领域的发展做出更大的贡献。









