在探索人工智能的无限可能时,大型语言模型(LLMs)无疑占据了举足轻重的地位。它们凭借卓越的自然语言理解和生成能力,在问答、翻译、文本创作等多个领域大放异彩。然而,随着模型体积的不断膨胀,对计算资源的需求也水涨船高,这在端侧设备上尤为棘手,因为这些设备的计算能力往往有限。从智能家居到智能座舱,端侧设备无处不在,它们对小型、高效的语言模型需求迫切。
在此背景下,小型语言模型(SLMs)的研究逐渐升温。微软作为行业巨头,凭借其深厚的研发实力,推出了Phi系列小模型,为资源受限的端侧环境提供了切实可行的解决方案。这一系列模型以较小的体积和较低的计算需求,实现了令人瞩目的语言理解和生成能力。
Phi-1作为系列的开山之作,基于Transformer架构,拥有1.3亿参数。尽管规模不大,但在Python编程任务上,Phi-1的表现却令人眼前一亮,尤其在Humaneval和MBPP基准测试中,其性能接近甚至超越了某些大型模型。这一成就为小型模型的发展奠定了坚实的基础。
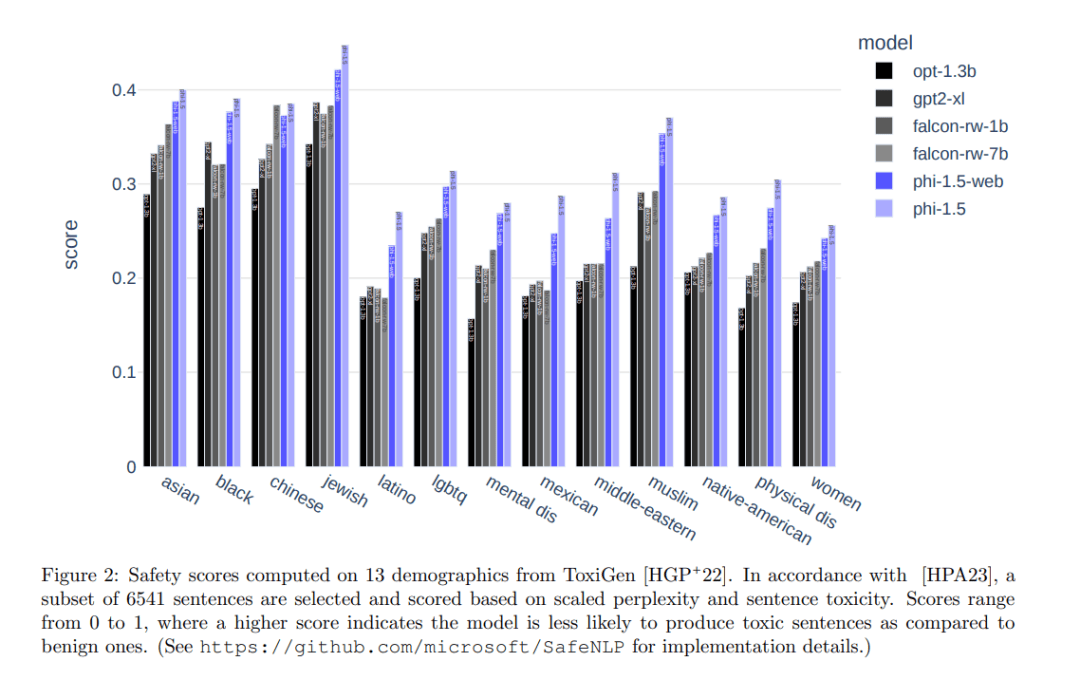
Phi-1.5在Phi-1的基础上进行了优化和扩展,同样拥有1.3亿参数,但训练数据得到了显著提升。通过引入涵盖科学、日常活动和心智理论等领域的教科书内容,以及高质量互联网数据,Phi-1.5在自然语言任务上的表现与比其大五倍的模型相当,甚至在复杂推理任务上超越了多数非前沿LLMs。
Phi-2则进一步提升了性能,拥有2.7亿参数。通过创新的知识转移技术,Phi-2在Phi-1.5的基础上加速了训练过程,并在基准测试中取得了显著进步。在多个复杂基准测试中,Phi-2能够匹配或超越比其规模大25倍的模型。Phi-2还在安全性和偏见方面进行了改进,减少了生成有害内容的可能性。
Phi-3系列则推出了三个不同量级的小模型:Phi-3 mini、Phi-3 small和Phi-3 medium。其中,Phi-3-mini拥有3.8B参数,性能接近或等同于市场上的大型模型。在MMLU和MT-bench等学术基准测试中表现出色。量化后的Phi-3-mini可在iPhone 14上实现快速推理,同时也可部署在Android或HarmonyOS操作系统的手机上。
Phi-3系列还包含了一个多模态模型——Phi-3-vision,融合了视觉和语言功能。它能够结合文本和图像进行推理,从图像中提取和推理文本,优化对图表和图像的理解。在小型模型中提供了出色的语言和图像推理质量。在PC的CPU上部署Phi-3-vision,通过量化技术减少模型大小,实现了高效的多模态问答。
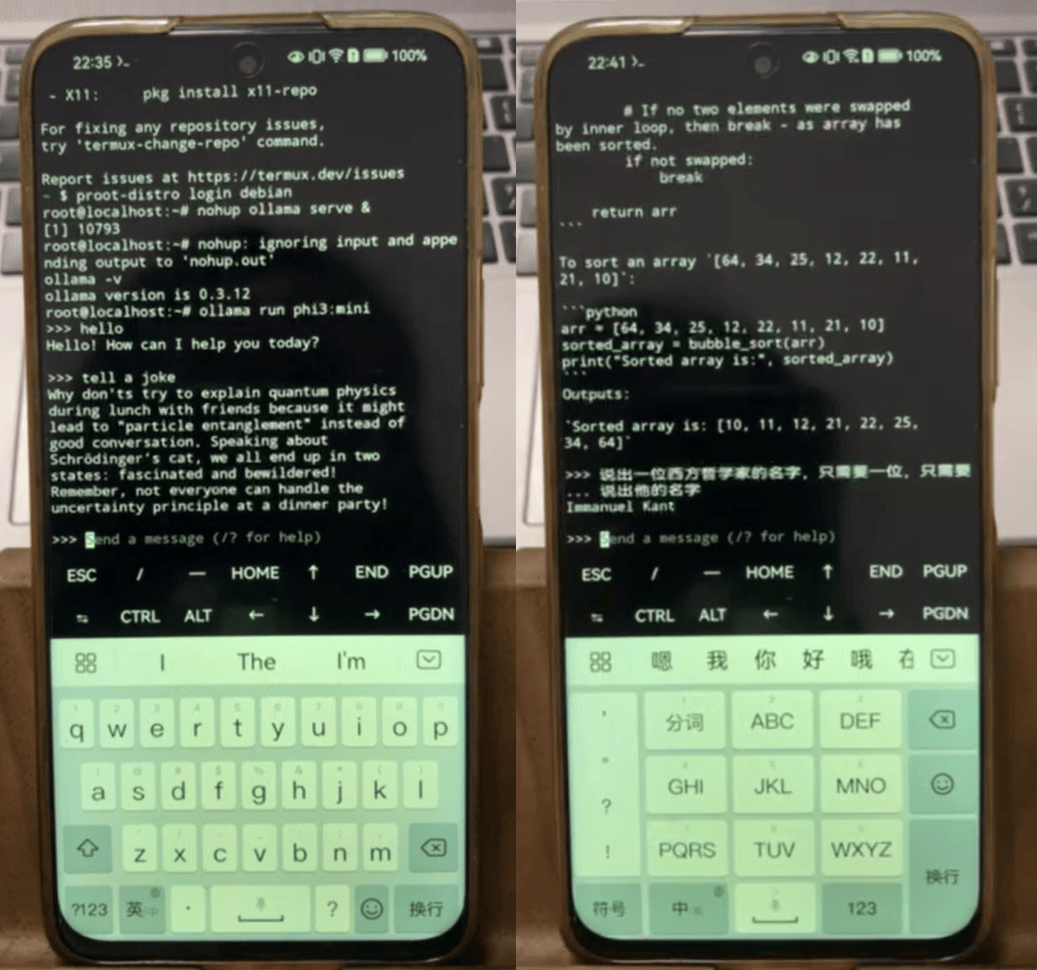

最新一代的Phi-3.5系列小模型则进一步提升了性能和灵活性。该系列包括Phi-3.5-mini、Phi-3.5-MoE和Phi-3.5-vision三个模型,分别针对轻量级推理、混合专家系统和多模态任务设计。Phi-3.5系列支持多种语言,并采用了组查询注意力机制和块稀疏注意力模块,以提高训练和推理速度。
Phi-3.5-mini专为遵守指令而设计,支持快速推理任务,适合在内存或计算资源受限的环境中执行代码生成、数学问题求解和基于逻辑的推理任务等。Phi-3.5-MoE则采用了混合专家架构,将多个不同类型的模型组合成一个,每个模型专门处理不同的任务,适合处理复杂的多语言和多任务场景。Phi-3.5-vision则继续发挥其多模态优势,在图像和文本推理方面表现出色。
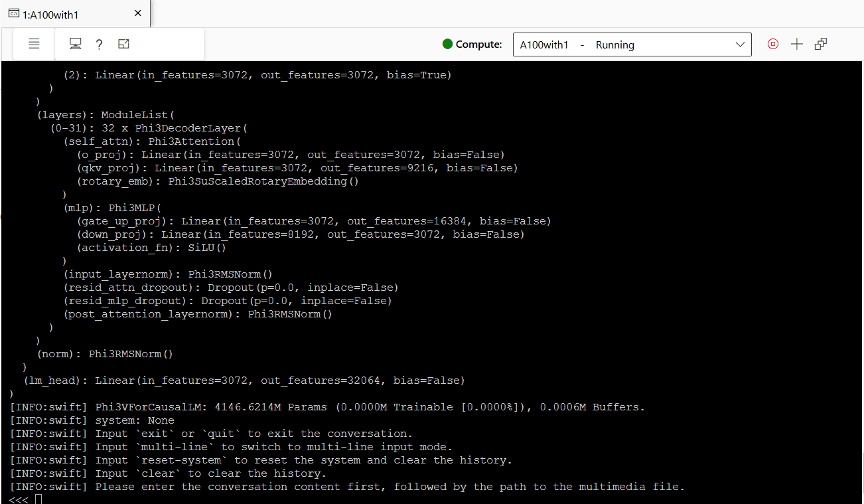
以Phi-3.5-vision为例,我们展示了其在GPU上的推理部署和测试过程。在Azure Machine Learning平台上,我们创建了一台A100 GPU,并安装了必要的软件和库。通过运行推理模型,我们实现了与Phi-3.5-vision的交互,包括文本问答和多模态问答。在测试过程中,Phi-3.5-vision展现了出色的性能和准确性,同时保持了较低的GPU显存占用。