在龙年即将落幕,蛇年悄然开启之际,一场科技界的“惊蛰”悄然上演。一家名为DeepSeek(深度求索)的中国初创公司,以其大模型DeepSeek-V3,在全球范围内引发了科技圈和华尔街的震动。
1月27日,美国人工智能主题股票遭遇抛售潮,其中英伟达股价暴跌16.97%,市值一日之内蒸发近6000亿美元,创造了美国历史上单日市值损失之最。这一事件的幕后推手,正是DeepSeek-V3。该模型发布后迅速登顶美国苹果App商店免费下载排行榜,其影响力可见一斑。
紧接着,在除夕夜前一晚的1月28日凌晨,DeepSeek又宣布开源其多模态模型Janus-Pro-7B,并声称在Geneval和DPG-Bench基准测试中击败了OpenAI的DALL-E 3和Stable Diffusion。这一消息再次震撼了科技界。
然而,DeepSeek的崛起也引发了美国的担忧。多名美国官员回应称,DeepSeek对美国构成了威胁,正对其开展国家安全调查。面对外部压力,360集团创始人、董事长周鸿祎在微博上表示,如果DeepSeek有需要,360愿意提供网络安全方面的全力支持。
DeepSeek的崛起无疑给全球科技界带来了巨大冲击。在软银宣布准备投资5000亿美元用于AI基础建设之际,DeepSeek-R1的发布更是让全球科技界为之震动。这是一个完全开源的模型,从代码到架构再到训练方法,都可以随意查看、修改和使用。据DeepSeek官方发布的数据,该模型在数学、代码、自然语言推理等任务上的性能,已经比肩美国OpenAI公司最新的o1大模型正式版。
DeepSeek的创新之处在于,它并没有盲目追求算力的堆砌,而是专注于算法的创新,从而减少了对计算资源的需求。据悉,R1完全抛弃了传统监督学习路线,通过动态路由算法压缩了80%的冗余计算,以在有限的运算能力中实现高性能。R1的训练成本也极低,其API定价远低于OpenAI的ChatGPT-o1。
DeepSeek的崛起让AI变得更加廉价、高效,或将成为大语言模型发展史上的典范。这一创新不仅让美国各大模型感受到了降维打击,也颠覆了他们传统的“烧钱”信仰。AMD宣布已将DeepSeek-V3模型集成到其GPU上,以实现最佳性能。而meta公司的员工则发文称,由于DeepSeek的低成本高性能,他们公司的人工智能部门已经陷入恐慌。
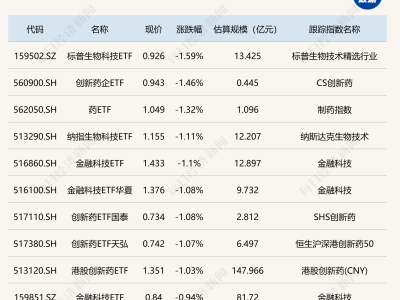
国内大厂也被DeepSeek的崛起所激励。阿里云在除夕夜加班发布了通义千问旗舰版模型Qwen2.5-Max,并声称在多项测试中全面超越GPT-4o、DeepSeek-V3、Llama-3.1等模型。这无疑展示了中国AI技术的快速进步。
然而,尽管DeepSeek在全球范围内引发了巨大关注,但谈及其已经“赢麻了”还为时尚早。虽然DeepSeek在中文语境下的表现较为优秀,但在文生图创作方面却令人失望。DeepSeek仍然依赖于美国的算力生态,其训练仍然依赖英伟达GPU。多位业内人士认为,DeepSeek的训练方式仍然依赖于堆积算力,而非真正的突破。
同时,DeepSeek也面临着恶意攻击和宕机的风险。由于其用户数的暴增和完全开源的技术生态,DeepSeek可能处于更高的风险之中。在实际使用中,用户也会发现DeepSeek宣告宕机的频次比之前要高得多。
尽管如此,DeepSeek的出圈仍然是中国AI算法的突破,值得我们肯定和自豪。DeepSeek的创始人梁文锋在回应“国运级别的科技成果”的盛赞时表示,团队只是站在开源社区巨人们的肩膀上,给国产大模型这栋大厦多拧了几颗螺丝。他的清醒和谦逊让我们看到了中国AI技术的未来希望。
DeepSeek的崛起不仅展示了中国AI技术的实力,也给全球科技界带来了新的挑战和机遇。我们期待在未来的发展中,DeepSeek能够继续保持其创新精神,为全球AI技术的发展做出更大的贡献。