近期,全球AI领域迎来了新一轮的震撼,DeepSeek R1、字节跳动的豆包1.5 Pro以及月之暗面的Kimi k1.5模型相继发布,这一系列动作迅速吸引了全球投资者的密切关注。特别是DeepSeek R1凭借其卓越的性能和仅为OpenAI近二十分之一的算力成本,让科技巨头英伟达(Nasdaq:NVDA)的股价一夜之间暴跌17%。
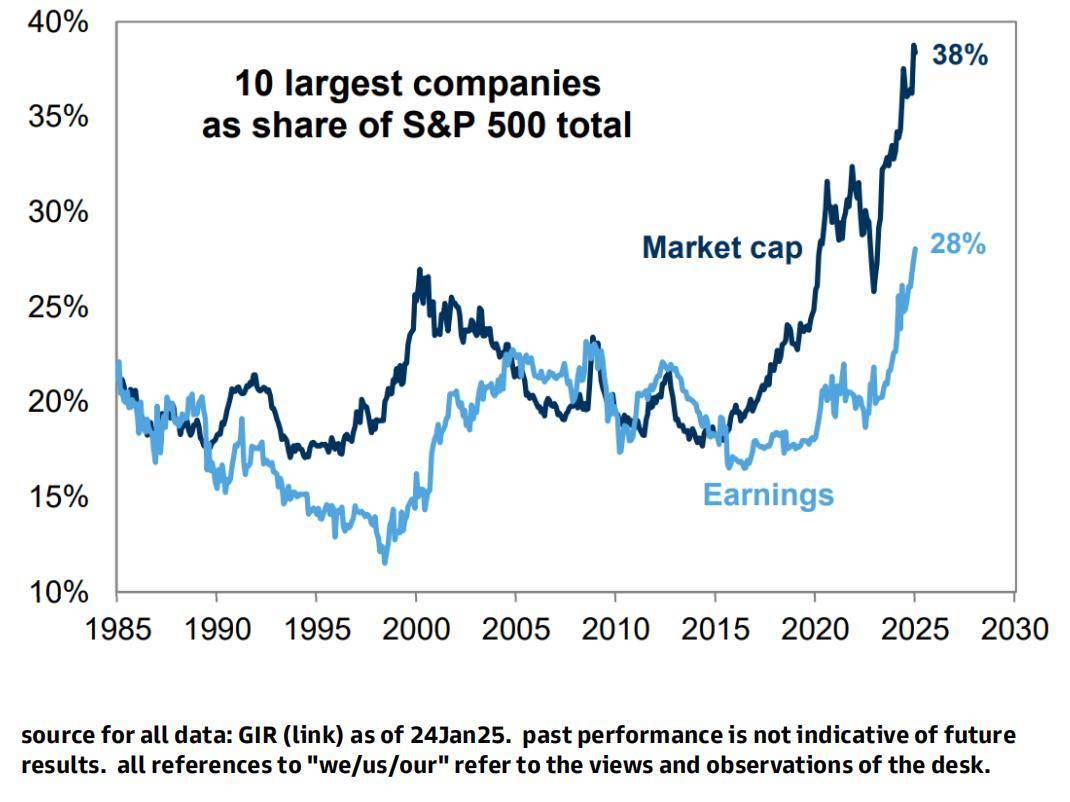
据相关报道,DeepSeek的出现引起了华尔街投资经理的广泛焦虑,尤其是那些重仓科技股的大盘股基金经理。美股七巨头在2024年为标普500总回报贡献了41%,而DeepSeek虽然尚未超越OpenAI的o3版本,但已经显著缩小了与早期o1版本的差距。更重要的是,DeepSeek的出现引发了市场对大模型价格战和算力需求下降的担忧。
尽管英伟达等科技巨头的股价在暴跌后有所反弹,但华尔街已经开始更为理性地分析“中国AI冲击”。DeepSeek的问世意味着更多新玩家的加入,算力需求或将持续增长,但未来的热点可能会从基础设施层转向应用层,更多AI公司有望从中受益。
首席全球股票策略师Peter Oppenheimer在最新报告中指出,DeepSeek大模型引发的股市修正标志着自去年秋季以来,“Magnificent 7”(七巨头)首次下跌超过3.5%。他认为这是一次修正而非长期熊市的开始,并预计AI领域更低价的新进者可能会增强市场对宏观经济环境的信心。
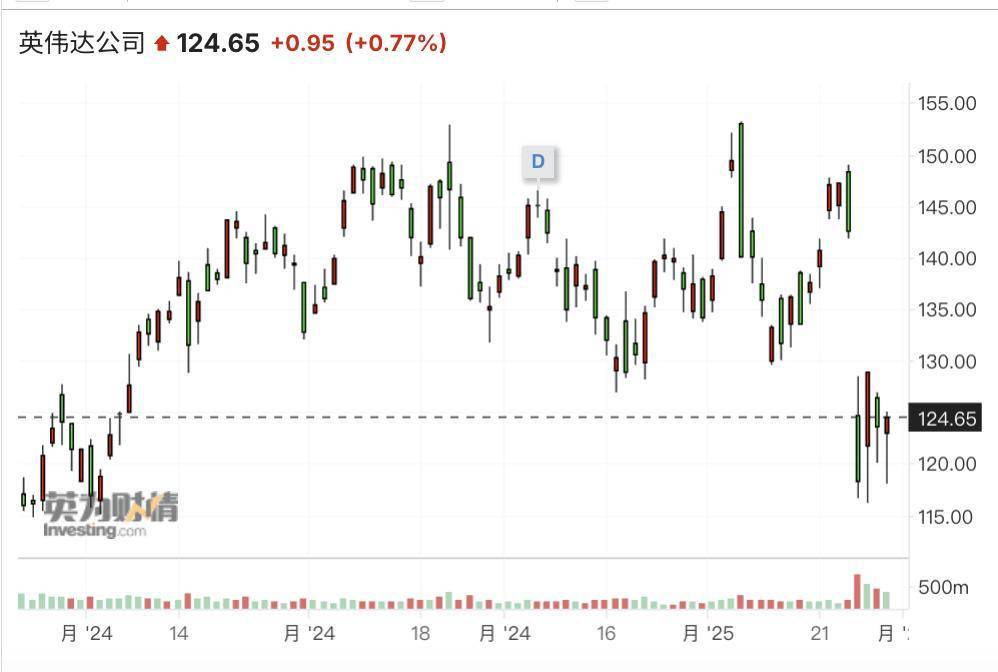
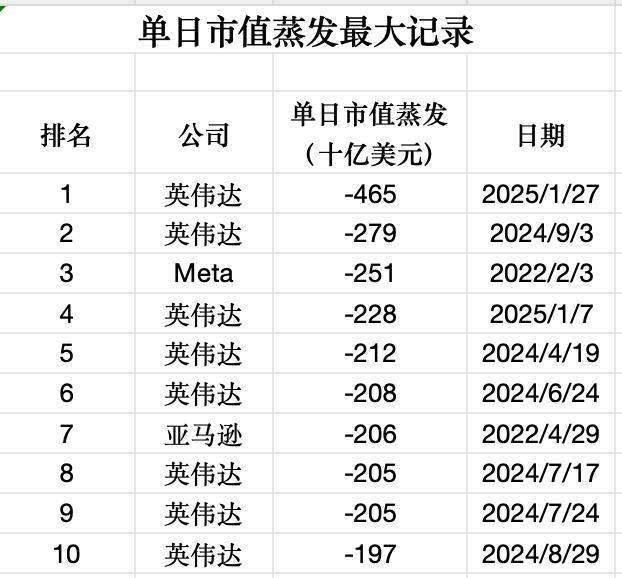
近期,华尔街基金经理的心情如同英伟达的股价一样经历了过山车般的起伏。1月28日,英伟达暴跌17%,随后几天股价上下波动,最终在31日收于124美元。一位华尔街中盘股基金经理表示,不仅英伟达暴跌,连电力股都受到了冲击,影响远超预期。
DeepSeek发布的推理大模型DeepSeek-R1以开源形式亮相,性能与OpenAI的闭源旗舰模型o1相当,但训练成本极低。这一突破不仅让硅谷感到焦虑,更暴露了AI领域长期依赖硬件堆砌与封闭生态的脆弱性。DeepSeek的训练主要基于meta的开源大模型Llama系列,并结合自研优化和大规模训练技术。
高盛指出,DeepSeek模型的低成本特点正在动摇投资者对整个AI生态系统的信心,尤其是对这种低成本模式是否意味着未来无需巨额支出和投资的质疑。一位AI相关科研人士表示,DeepSeek的原理和训练模式与OpenAI o1存在较大差异,且更直观、可解释,这得益于中国企业在预算和高端芯片有限条件下的优化训练流程。
随着AI领域的快速发展,谷歌、meta、亚马逊、微软、苹果等企业的资本支出大幅增长,2024年的资本支出预计将达到2000亿美元。然而,DeepSeek的出现让投资者开始重新审视AI投资的必要性,尤其是随着进入门槛的降低,AI领域可能出现资本雄厚的互联网巨头与初创企业之间的竞争。
对于投资者而言,当前最大的问题是抄底还是观望。观望者认为,DeepSeek带来的冲击可能导致投资者重新审视AI投资的必要性。而抄底者则认为,随着应用场景的加速普及和多模态要求的提高,算力需求将持续增长,英伟达等核心企业仍将占据主导地位。
![]()
高盛科技分析师强调,AI主题的下一阶段演进可能会从基础设施层转向应用层,如AI智能体、企业应用场景等。这将带来更线性、可理解的资本回报。不同行业的格局将发生变化,如半导体行业可能因AI训练计算成本下降而面临股票抛售压力和估值受压;软件行业则可能受益于效率提升和成本下降,加速企业AI的采用。
中国AI企业的发展大超预期,DeepSeek的爆红无疑增加了相关主题的吸引力。OpenAI原全球市场应用负责人表示,中国在未来AI竞赛中不一定会落后,且能用更少的GPU构建模型。高盛认为,依托高性能和低成本优势,中国AI企业在全球范围内具备竞争力,特别是在To C应用方面具备先发优势。