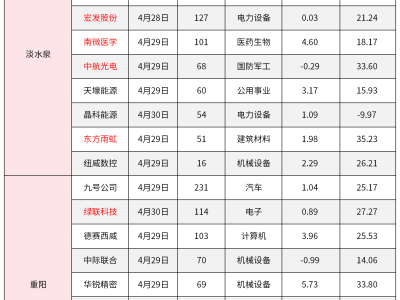
在AI领域的激烈竞争中,大模型的较量正逐步进入白热化阶段。近期,一位业内人士在与朋友的交谈中,深刻剖析了这一领域的现状。
他指出,当前各大厂商的大模型之间的差距日益缩小,评价它们时,甚至只能使用“遥遥领先”或“远超同行”等相对模糊的表述。从基准测试数据来看,许多模型的表现已远超早期的DeepSeek R1和GPT-4,但在进一步提升性能方面的空间已变得十分有限。真正的差异,更多体现在实际应用的方式和效果上。
这一观察引发了对于大模型竞争是否已进入存量博弈阶段的思考。所谓“存量”,必然伴随着激烈的竞争,即“内卷”。那么,这场“内卷”究竟体现在哪些方面呢?
算力成本、数据质量和场景渗透,被认为是当前大模型竞争中的三大核心要素。在算力成本方面,各厂商纷纷寻求在不牺牲性能的前提下降低成本。例如,阿里家的Qwen3通过“混合推理”技术,实现了对简单和复杂问题的差异化处理,显著降低了部署成本。腾讯的混元T1则通过稀疏激活机制,提升了算力利用率。百度文心大模型虽然在具体成本上未公开,但其推理速度在工业级场景中的优势显而易见。
数据质量的竞争,则从数据的“广度”转向了“深度”。阿里Qwen3的训练数据量高达36万亿token,支持多种语言和方言,数据质量具有普适性。百度文心一言则依托搜索、地图等产品积累了真实用户行为数据。腾讯混元通过开源生态积累开发者数据,在游戏和内容生成领域具备独特优势。字节跳动则通过抖音、今日头条等平台捕捉用户偏好数据,使内容生成模型更加贴近用户需求。
场景渗透的竞争,则是从“技术堆叠”向“价值创造”的转型。Qwen3在电商、金融、医疗等领域提供定制化解决方案。百度文心一言则嵌入搜索、地图、智能音箱等产品,形成了闭环。腾讯混元聚焦游戏和内容生产,抢占多模态赛道。字节跳动则将大模型融入内容生产流程,甚至用AI生成短视频脚本,打通了技术到内容的链条。
然而,这场“内卷”背后,却隐藏着一个更深层次的矛盾。当技术突破趋缓时,频繁的开源和相互“吊打”是否意味着在掩盖真正的技术瓶颈?业内人士认为,确实存在这种可能性,但并非完全没有进步,而是技术方向发生了微调。
以数据为例,阿里Qwen3-235B-A22B虽然总参数量高达2350亿,但每次实际用到的参数只有220亿,激活效率并不高。这反映出“轻量化”策略已成为一种妥协,单纯堆参数已无法带来显著效果。腾讯混元T1同样面临这一问题,其总参数量高达3890亿,但激活参数量仅为520亿。百度文心大模型的4.5 Turbo总参数量1970亿,每次推理最多用到28亿参数。这些都说明,参数量已不再是唯一衡量标准,激活效率成为新的竞争点。
技术优化路线方面,阿里推出的“快慢思考”混合推理,本质是对Transformer架构的适应和改造。腾讯混元的稀疏激活机制也受限于硬件兼容性和算法复杂度。这些优化更像是在延长现有架构的生命周期,而非真正的技术突破。
因此,短期来看,这些优化确实缓解了算力成本压力,但只是对现有技术框架的修补。长期来看,技术瓶颈并未消失,而是转变为了“效率瓶颈”和“场景适配瓶颈”。真正的突破还需依靠底层架构的创新。
面对这一现状,大厂在“模型卷”的浪潮中该如何找到自身的核心竞争力?是继续在技术细节上抠来抠去,还是将精力放在技术实际应用和生态建设上?业内人士认为,技术细节优化只是手段,场景落地和生态协同才是根基。
对于大厂而言,价值锚点的核心在于能否真正解决实际问题,而非单纯追求技术指标的极致。在这方面,“三重共振”——云厂商、行业应用和MCP协议——成为关键。MCP协议本质上重新定义了企业与AI的合作规则,使AI能够自动找到企业的数据库、API和业务流程,实现跨系统操作。
以高德地图为例,如果接入MCP协议,其导航建议将不再局限于简单的“绕开拥堵”,而是能结合用户消费记录推荐周边餐厅,甚至直接跳转到外卖App下单。这背后是MCP协议将高德的数据与阿里云的AI能力打通的结果。
MCP协议如何驱动ToB范式变化?主要有两点:一是从“模型为中心”转变为“数据为中心”,使重点转向数据流通;二是从“孤岛”转变为“协同”,实现企业内部系统的全面打通。
打通后,MCP协议从一个简单的工具变成了生产力基础设施,让AI不再局限于参数规模和推理速度,而是通过数据协同和场景嵌入,成为企业运营的“操作系统”。这正是企业的刚需所在。
在这一趋势下,未来可能会出现新的企业级平台,它们或许不具备通讯、协同功能,但至少能将企业的各种业务流程整合起来,实现高效运营。
而这一切的变化,都将在未来的竞争中逐步显现。DeepSeek R2的推出,或许将成为这一变革的重要节点。