近期,AI领域迎来了一股新的热潮,Deepseek凭借其创新技术和迅猛的用户增长,迅速成为业界的焦点。通过采用稀疏激活的MoE架构、MLA注意力机制优化及混合专家分配策略,Deepseek不仅实现了高效的训练和推理能力,还大幅降低了API调用成本,树立了行业的新标杆。
尤为引人注目的是,Deepseek在用户增长方面的表现堪称奇迹。仅在发布后的7天内,其用户数就突破了1亿大关,这一速度远远超过了OpenAI的ChatGPT,后者用了整整2个月才达到同样的里程碑。这一成就不仅彰显了Deepseek的技术实力,也预示着AI市场即将迎来新的变革。
随着Deepseek的火爆,关于其本地部署的教程也在网络上如雨后春笋般涌现。然而,这些教程往往只强调了Deepseek的强大功能,却对其不同版本之间的差异语焉不详。尤其是“蒸馏版”与“满血版”Deepseek-R1之间的差距,对于普通用户而言,更是一头雾水。
事实上,目前公开发布的小尺寸DeepSeek-R1模型,都是通过Qwen或Llama从R1中蒸馏而来,以适应不同性能设备的调用需求。这意味着,无论是7B还是32B的DeepSeek-R1,在本质上都更像是“R1味儿”的Qwen模型,与“满血版”671B的R1存在显著的差距。
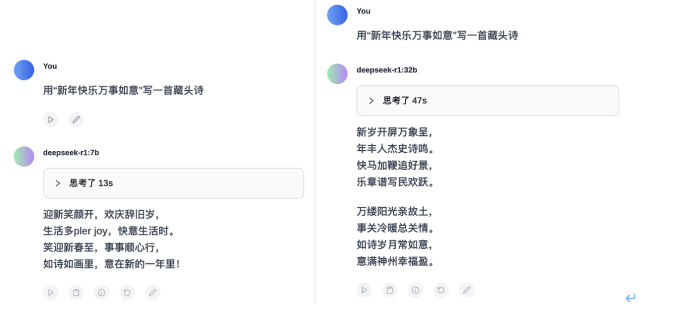
为了直观展示这种差距,我们进行了一系列测试。在语言能力测试环节,我们要求7B、32B和671B的DeepSeek-R1分别用“新年快乐万事如意”写一首藏头诗。结果令人惊讶,7B版本的R1竟然出现了明显的bug,输出结果既没能“藏头”,也不像一首“诗”,甚至还在文中夹杂了英语。相比之下,32B的R1虽然押韵方面存在瑕疵,但胜在对仗工整,内容上也没有逻辑错误。而“满血版”的R1则表现最为出色,不仅对仗工整、韵脚得体,还给出了诗词的赏析内容。


在联网总结测试环节,我们将R1与网络搜索相结合,测试不同尺寸下对于网络内容的汇总能力。结果发现,7B模型的输出结果并不稳定,偶尔会出现对诗词理解出现偏差的情况。而32B的R1输出则相对稳定,对诗词内容理解的准确性有了较大提高。当然,“满血版”的R1依旧表现最为优秀,不仅能够完整展示诗句内容,还会在答案中增加点评与背景陈述。
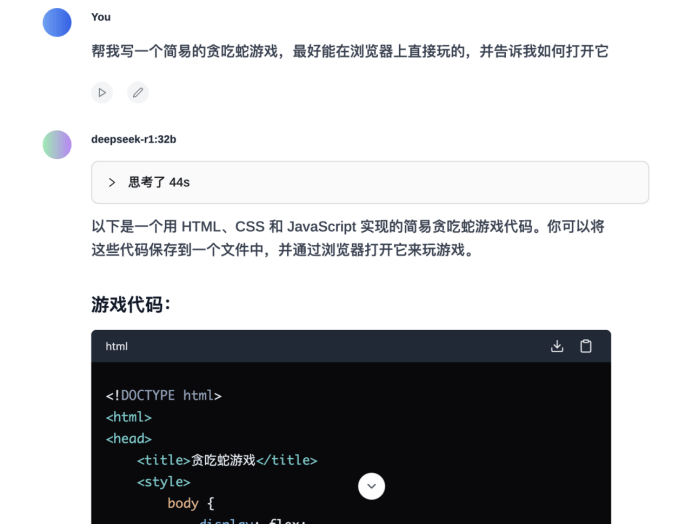
我们还进行了逻辑推理测试和代码能力测试。在逻辑推理测试中,我们发现无论是7B还是32B的模型,在数学运算能力方面都表现得相当出色。然而,在代码能力测试中,7B的Deepseek-R1生成的游戏程序存在bug,无法正常运行。而32B的模型则能够生成可以正常运行的贪吃蛇游戏程序。

从这一系列测试中不难看出,DeepSeek-R1的7B和32B版本与“满血版”671B之间存在显著的差距。因此,对于普通用户而言,本地部署更多是用来搭建私有数据库或让有能力的开发者进行微调与部署使用。官方测试结论也显示,32B的DeepSeek-R1大约能够实现90%的671B的性能。然而,即便如此,本地部署的门槛仍然较高,不仅需要高性能的硬件设备,还需要额外的联网功能或本地化数据库支持。
对于大多数普通用户而言,费劲心力搭建的本地大模型可能未必有市面上主流的免费大模型产品来得简单、方便、效果好。因此,在选择是否进行本地部署时,用户需要权衡利弊,根据自身需求和条件做出明智的决策。